
In my first post on Data Readiness, I introduced the notion of a Data Readiness activity to provide the AI development team with the political power to make the resources (typically data and subject matter experts) they need available to them – and ensure the AI application is perfected to make it useful to the business.
Digging deeper, how are the project responsibilities split between the Data Readiness activity and the other parts of the project?
At the start, the Project Sponsors have a business problem that seems to be a good use case for AI. It involves computer understanding of natural language, or images/video, plus the need to characterise a real world situation and select an appropriate action to take.
Although this is a new type of project, the standard activities around the project start-up occur. This includes defining the project charter, scope, timeline, budget and resources that are to be assigned to the project.

When the project is ready to begin, the first Data Readiness activity bootstraps the project with the initial selection of data and goes on to locate more data and ensure it is of the quality and reliability to make the AI Application work.
Acquiring data
The AI Development Team need data that forms the knowledge base to train the AI model on. They need details of the different perspectives (roles) of the people who will interact with the system and how that impacts the interpretation of the requests they make, and finally they need details of the systems (MCP tools) to call to retrieve real-time information and take action.
Locating this information can take time and knowledge of the organization’s operation to identify where this data is likely to be and who is responsible for it. Some teams will have a data catalog, others may be more sophisticated, with a digital (data) product marketplace, both of which can help locate data. In other circumstances, data may need to be extracted from production systems or data platforms, to be examined for suitability.
Data Readiness works with the Data Engineering teams to provision the candidate data to where the AI development team can access it. This includes negotiating access from the data owners and the development of data pipelines to supply the data to the AI development team with the data engineering teams. Typically, data provisioning begins with the delivery of a snapshot to allow some experimentation to take place. If the data is effective, a longer term solution must be arranged to ensure the regular capture, management, retention and delivery of this data for the production development and operation of the AI application.
Often the emerging AI Application is using data sources that have not been processed before – such as call logs, email, engineering notebooks, documentation and other media. The Data Readiness activity must verify the ownership and licensing of this data and ensure that governance requirements (such as legal restrictions and corporate guidelines) are supported.
With the data delivered, Data Readiness seeks feedback from the AI Development Team on their progress and likely future needs. Together, they gather feedback from Subject Matter Experts and the Project Sponsors to agree next steps and the focus of the next iteration.
Finally, as the project moves closer to pilot and production deployment, Data Readiness works with the IT and Business Teams that will integrate the AI application both into the operational systems and the business at large.
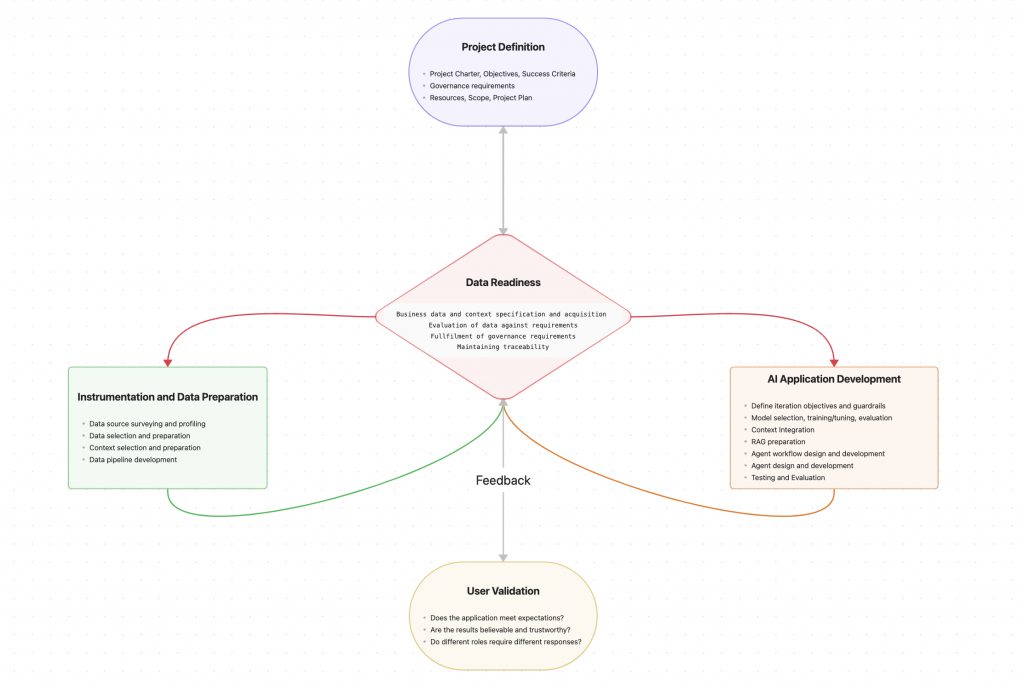
The flow diagram above shows the data readiness activity at the heart of an AI project. This is merely a perspective, no doubt reflecting my biases :). With such a collaborative effort, each activity has an important role to play, and open communication and transparency is key to its efficient operation. In my next blog, I will consider how this open communication and transparency is achieved.
This is blog 2 in the Data Readiness series.