In my last post, The Egeria Advisor: Casting Out Egeria Expert – Lessons Learned, I shared how we expanded the data scope of the Egeria Advisor to include core code repositories like egeria-python, egeria (Java), and egeria-workspaces. This expansion was essential to support diverse community perspectives, ranging from Data Engineers and Developers to Data Stewards and Governance Officers. We also took a first pass at traffic management by structurally isolating the Python library into separate target collections to simplify initial query routing.
However, as we opened up the floodgates to these broader repositories, we ran into an important realization: simply separating data into different pools is only part of the solution. If your ingestion engine processes all files with the exact same parameters, your vector store ends up with fragmented, disconnected concepts.
The realization came when we stopped viewing ingestion as a uniform conveyor belt and started treating it as a data profiling exercise. Just as you wouldn’t ingest enterprise data without profiling its schema and distributions, we needed to analyze our documents to understand the structural and content patterns. Only by profiling the native characteristics of these files could we build an ingestion framework capable of presenting data to the LLM in a truly meaningful way.
The Profiling Challenge: Fragmented Context
Initially, even after splitting our repositories into distinct collections, we were still using uniform ingestion parameters across the board: a standard 512-token or 1000-character chunk size with a basic overlap.
When we began profiling what was actually happening to the text during this process, we discovered why our retrieval quality was inconsistent. A rigid, character-based limit completely ignored the structural patterns of how technical documentation is written.
For example, our analysis showed that a tutorial or user guide typically explains a multi-step configuration process over a specific sequence of paragraphs. A blind character limit frequently sliced those patterns mid-explanation. The prerequisites might end up in one chunk, while the execution steps landed in another. If a user asked about execution, the LLM received the second chunk without the necessary prerequisites, leading it to hallucinate the missing details.
Our profiling made it clear that different content patterns demand distinct retrieval behaviors:
- Code queries often benefit from retrieving a wider net of smaller, precise snippets (a higher
top_k). - High-level conceptual definitions require strict precision (a higher
min_score) and larger windows to keep explanations intact.
Step 1: Incremental Profiling and Tuning the Documentation
When looking at a massive documentation corpus, it helps to realize that data profiling doesn’t have to be a massive, all-at-once automated hurdle. For smaller, highly targeted collections like mine, profiling can be done incrementally, guided entirely by quality results.
In larger enterprise RAG systems spanning millions of documents, you generally have to automate your profiling to a certain depth first—using scripts to analyze token distributions, clustering patterns, and file types at scale—before leaning on quality metrics to flag areas for deeper analysis. But on a project like the Egeria Advisor, we were able to start with the most obvious, structural content patterns written right into the Egeria repository’s directory layout, and then refine our approach as quality issues emerged.
By looking at the native organization of the MkDocs source, we mapped out three highly visible patterns and split the egeria_docs repository into specialized sub-collections custom-tuned to those structures:
egeria_concepts: In our profiling, we noted that concepts are essentially short, glossary-style entries. Because they are concise and self-contained, we assigned them a tight chunk size of 768, an overlap of 150, and set a higher similarity threshold (min_scoreof 0.45) to ensure the LLM only fetches exact conceptual matches.egeria_types: Thetypesfolder natively contains data types, schemas, asset models, and UML/attribute tables. These are naturally medium-sized blocks of information. We tuned this collection with a chunk size of 1024 and amin_scoreof 0.42 to prevent structural tables and schema definitions from being fragmented.egeria_general: This bucket was reserved for the general pages, best practices, and guides that vary in size and layout. Here, we expanded the chunk size to 1536 tokens with a 300-token overlap and a lowermin_score(0.38), ensuring that complex, multi-paragraph instructions stay bound together.
This incremental approach allows us to invest time and effort based on need. We could start with these obvious baselines, and if a particular class of tutorial still resulted in a hallucination, we could isolate those files, profile their specific content patterns, and tune their parameters individually. By shifting to this feedback-guided, profiled ingestion strategy, our document-based hallucination rate dropped from roughly ~80% down to where it seems useful.
Step 2: From Text Chunks to Abstract Syntax Trees (AST)
While tuning paragraph sizes resolved the documentation issues, code files required a different strategy. Using arbitrary character limits on code files often cuts right through loops, functions, or classes, separating a method signature from its internal logic or isolating a docstring from its parent function.
To fix this for our Python repositories, we transitioned away from character-based text splitting entirely and implemented AST (Abstract Syntax Tree) parsing.
Instead of measuring characters, the ingestion engine parses the code structurally according to Python’s native syntax rules. It detects where a class or function begins and ends, drawing natural chunk boundaries around the code. This guarantees that an entire method—including its decorators, signature, internal logic, and docstrings—is preserved as a single logical unit inside the vector store.
While implemented for Python, I now need to go back and do this for Java as well…its on the Backlog.
Step 3: Resolving Non-Determinism via Intent, Perspective, and Multi-Agent Coordination
Fixing our ingestion parameters and moving to AST parsing meant our vector collections were finally full of reliable, structurally sound context blocks. However, this precision introduced a downstream traffic challenge: our early prompt-based routing gave rather unpredictable results as prompts failed to query the most appropriate source.
A fundamental issue with many generative AI applications is that you do not natively get repeatable, deterministic responses. Because LLMs operate on probabilistic next-token predictions, relying on a single complex prompt to handle routing or interpret intent—especially on small, local models—is highly unstable. Consider fundamental data management terms like Glossary, Governance Process, or Information Supply Chain. These concepts are woven across every single layer of our repositories. If a user asks a question containing the phrase “Information Supply Chain,” a basic prompt router struggles to determine whether they need a high-level conceptual overview, an administrative report, or programmatic Python example to map it out.
To solve this non-determinism, we moved away from simple prompt routing to a coordinated multi-agent architecture. While we utilized some components from the BeeAI framework, we also rolled out our own coordination logic to manage agent collaboration effectively. We deployed independent, specialized workers like the DocAgent for explanations, an ExamplesAgent for generating runnable code snippets, and a dedicated CLICommandAgent to power our interactive command lookup tools.
This backend coordination layer quickly demanded a matching front-end interface strategy to help the user guide the engine. The interface evolution happened in two clear stages:
- The CLI (
egeria-advisor): First, we introduced a dedicated command-line interface equipped with--interactiveand--agentmodes. Backed by a specializedCLICommandAgent, this allowed developers to run quick command lookups (viahey_egeria) directly from their terminals, instantly routing terminal requests to precise scripting data. - The Web UI SPA (Single Page Application) : To expand the tool to our broader business personas, we then built a dedicated web-based Single Page Application served by FastAPI.
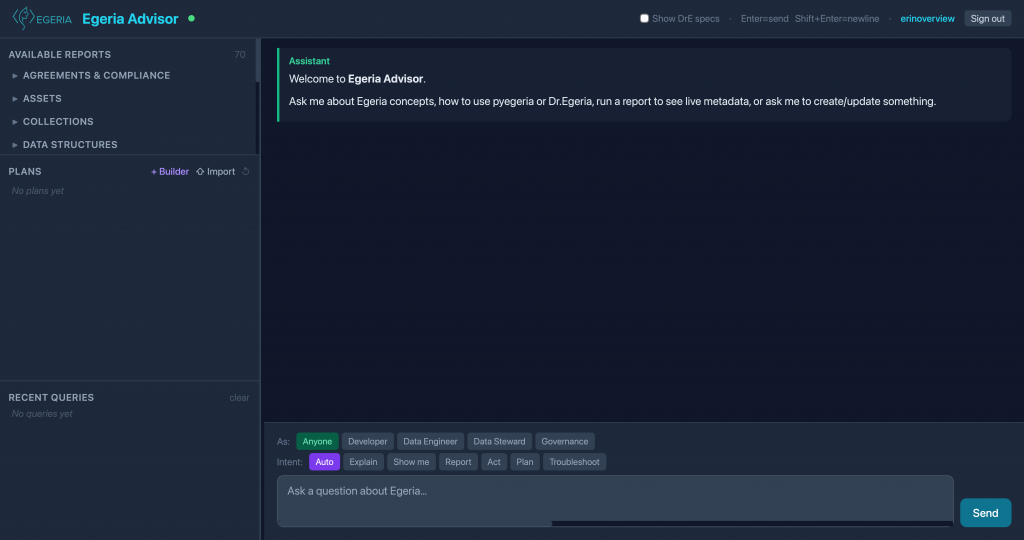
Rather than forcing the backend to blindly guess user intent from an ambiguous phrase, the Web UI provides explicit controls for the user to signal their exact situational context. As seen in the interface, a user can dynamically toggle their active Perspective selector (Anyone, Developer, Data Engineer, Data Steward, Governance) and explicitly lock in their operational Intent (Auto, Explain, Show me, Report, Act, Plan, Troubleshoot).
Crucially, stabilizing the system meant combining this backend framework with the context controls in our front-end Web UI.
Rather than forcing the system to guess blind intent from an ambiguous phrase, the Web UI provides explicit controls for the user to signal their situational context. As seen in the interface, a user can dynamically toggle their active Perspective(Anyone, Developer, Data Engineer, Data Steward, Governance) and explicitly choose their specific query Intent (Auto, Explain, Show me, Report, Act, Plan, Troubleshoot).
By utilizing these explicit constraints, we establish deterministic routing rules to construct the right kind of response. If a user asks about a Glossary with a Governance perspective and an Explain intent, the system knows to route directly to our conceptual documentation to deliver a business-aligned definition. If a different user queries that exact same Glossaryterm but switches their perspective to Data Engineer and their intent to Show me, the engine bypasses the text and invokes the ExamplesAgent to return runnable Python script structure.
By wrapping the probabilistic model within these deterministic guardrails, we ensure the routing is entirely repeatable, pulling from the appropriate data source to shape a response tailored precisely to the user’s focus space.
The Next Step: Activating the Environment via MCP
With our ingestion tuned and our multi-agent coordination stabilized (at least for now), the Egeria Advisor evolved into a reliable local reference engine. It understood who was asking, what they intended to find, and exactly where that context lived.
But answering questions is still a passive exercise. A true collaborator shouldn’t just explain how a system works; it should be able to actively interact with it.
In our next blog installment, we will explore how we migrated our backend to streamline the Advisor’s local footprint, and how we integrated the Model Context Protocol (MCP) to turn the Advisor from a passive reference assistant into an active administration tool capable of pulling live reports and executing commands directly against an up-and-running Egeria platform.
As always, feedback is welcome!