In my last post, The Egeria Advisor: Sharing the Journey, I introduced the foundational vision behind the Egeria Advisor—injecting “Context Intelligence” into AI applications by leveraging organizational and situational context to provide more useful results. But before you can build an intelligent ecosystem, you have to get the fundamental plumbing right.
My first attempt at that plumbing taught me that even the most powerful, popular AI toolkits are not a magic bullet out of the box. If your underlying data architecture doesn’t align with the native structure of your information and the diverse needs of your community, you will likely struggle with inconsistent, imaginative answers.
Here are the core architectural insights gained while transitioning from a simple prototype to a more useful, structured advisor.
Lesson 1: Frameworks are Accelerators—But Architecture is Key
When building a local Retrieval-Augmented Generation (RAG) pipeline, it is easy to assume that assembling a standard, high-quality toolkit will yield great results immediately. With the help of some AI coding agents, I set out to build an initial ingestion pipeline called Egeria Expert.
I brought together an array of popular components for the problem: Docling for parsing, Milvus for the vector database, basic orchestration frameworks, and LM Studio driving a Qwen2.5-7B-Instruct-1M model.
I loaded up the database, fired up the model, and pointed it strictly at the egeria-docs repository. However, the initial answers frequently suffered from inaccuracies and hallucinations. I adjusted the standard tuning knobs—modifying chunk sizes and lowering the model’s temperature—which provided modest improvements, but the system remained inconsistent.
The takeaway: Off-the-shelf tools and popular frameworks are fantastic accelerators, but they aren’t a substitute for tailored architecture. If the system doesn’t account for the native characteristics of the data you are feeding it, the utility of the output will hit a ceiling.
Lesson 2: Align Data Scope with Diverse User Personas
When I analyzed why the prototype was hitting a wall, I realized I was treating the Egeria ecosystem as a completely homogeneous block of text, while simultaneously bottlenecking the scope of our data.
Initially, the pipeline was fed entirely by the egeria-docs repository. Egeria’s web presence is an incredibly rich, structured corpus of over 6,000 files, including 4,208 markdown documents. It is built using MkDocs with immense care. For general, conceptual, and high-level platform questions, this documentation collection is highly valuable.
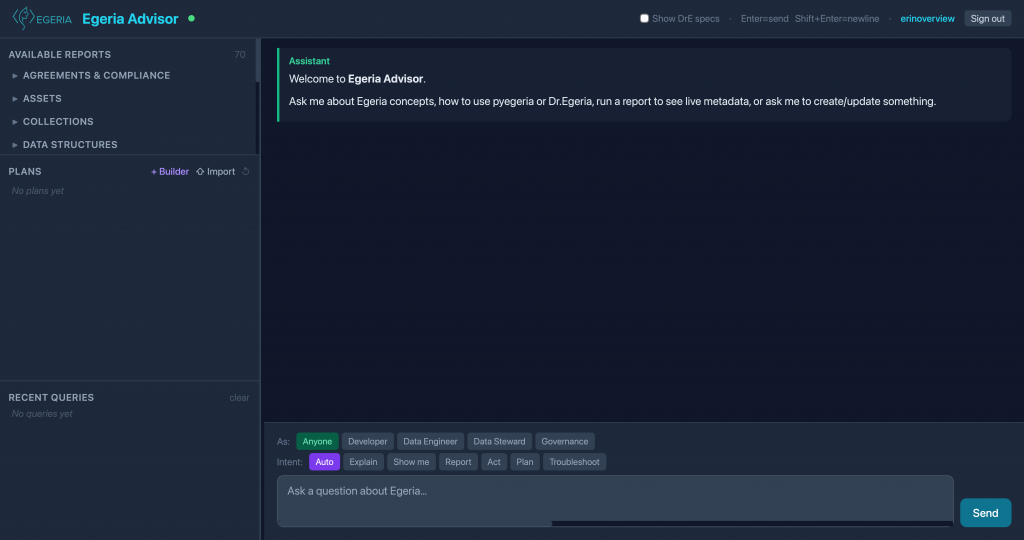
However, as I interacted with the system, I started asking questions that simply weren’t contained in the core documentation—practical and implementation-level questions of interest to our broader community. We want Egeria Advisor to serve a diverse group of stakeholders, including Data Engineers, Data Stewards, Data Scientists, Developers, Subject Matter Specialists, Governance Officers, and Security teams. Each of these groups brings a distinct perspective and a different class of inquiry.
If a developer asks how to interact with a metadata asset using the Python SDK, or a data steward asks what Report to use to find Governance Definitions, the Egeria documentation doesn’t provide factual text to support the answer. Without the necessary implementation data in the vector store, the local LLM was forced to guess, resulting in a high rate of factual errors.
To build a genuinely useful resource for both the technical and business perspectives in the community, the scope of data ingestion must expand to meet the coverage needs of these diverse use cases. To support these varied personas, we expanded our data estate to pull in the core implementation repositories:
egeria-python: The Python SDK and environment.egeria: The core enterprise Java repository.egeria-workspaces: A quick up and running environment, samples, and tutorial Jupyter Notebooks.
Lesson 3: Broadening Ingestion Scope Demands First-Pass Routing
Expanding our repository coverage solved the data gap, but it immediately introduced a new challenge: traffic management. I put each of these new repositories into their own separate vector collections, but the system initially struggled to determine where to search for specific answers. Everything was available at once, causing significant context noise. The model would frequently pull raw code snippets when a user wanted a conceptual overview, and vice versa.
When you add more sources to a RAG system, you have to work out how to efficiently navigate them. The first step is knowing how to route queries.
To make routing manageable, we looked at the structural roles within the egeria-python environment and divided it into distinct, isolated target collections:
pyegeria: Files organized to provide a friendly facade over Egeria’s Java-based Open Metadata Access Services (OMAS).pyegeria_cli: Separate script files containing specific command-line utilities.pyegeria_drE: The language parser and processing engine for handling Dr.Egeria markdown automation.
The goal of this breakdown was less about fine-tuning individual code chunk parameters (which came later), and more about isolating specific topics. For instance, by splitting the collections, we could easily route specific questions regarding the Dr.Egeria automation language directly to the pyegeria_drE collection, rather than polluting the general SDK search space.
Using early, prompt-based routing, we guided the local LLM to inspect the user’s incoming query and target the correct repository collection. This initial pass at traffic isolation marked the official transition from the exploratory “Expert” prototype to the core framework of the Egeria Advisor.
The Next Step: Coordination and Multi-Agent Evolution
This early phase was focused almost entirely on Coverage and First-Pass Routing—ensuring the data was there and providing a basic mechanism to navigate it. But routing is a living capability that must constantly adapt as use cases grow.
Relying on a single prompt to orchestrate traffic for an expanding data estate proved far too fragile, especially as enterprise acronyms began crossing boundaries. To improve precision, we needed to move beyond simple prompts and step up to a coordinated multi-agent architecture. While we utilized some components from the BeeAI framework, we also rolled out our own coordination logic to properly manage agent collaboration.
In our next blog installment, we’ll look at the next major evolution of the Advisor. We will shift from basic coverage into Context Intelligence, exploring how we introduced role-based perspective signals, intent-aware routing, and micro-parameter tuning across our collections. We’ll also cover how the architecture grew to support explicit use cases like automated example generation, template lookups, and feedback loops.
As always, feedback is welcome!